So You Want to Be a Hacker? Part II: The Hex Editor
Table of Contents
Part II: The Hex Editor
Let’s get started, then. Today we’ll be looking at a simple example archive format, as a springboard to talk about the “standard” parts of a game data file. Keeping this sort of template in mind as you gaze at an unknown format will be a great help to try to make sense of the random-looking bytes you run across.
The game we’ll be looking at for the moment is CROSS†CHANNEL (the trial edition download link is at the bottom of that page), which has a translation project already in progress. So, grab a copy if you like, and let’s take a look.
(Historian’s note: FlyingShine, the developer and publisher of CROSS†CHANNEL, unfortunately went bankrupt in 2019. Its site is no longer available. Likewise, the mentioned fan translation project is also no more, and CROSS†CHANNEL itself is officially licensed, translated, and available from MoeNovel on Steam. As for the trial edition used in this tutorial, we are pleased to provide a copy of it here so you can still follow along.)
Inside, beyond the executable and such, we’ve got just a few files: bgm.pd, cg.pd, script.pd, se.pd, and voice.pd. This is pretty typical: most games don’t ship with every sound clip and image in its own file, but collect them into a few data archives that can be random-accessed by the game engine. Extracting the separate files from these archives is the first step in attacking a game.
Now it’s time to fire up one of the hacker’s favorite tools, the hexadecimal editor. This is a relatively simple utility which just displays the raw bytes from a file with their positions… more advanced features often include the ability to interpret common data formats (integers and floating point numbers, etc.), comparing files, and especially searching for desired patterns. Personally, I use the Mac utility HexEdit (historian’s note: that software has not been updated since 2012, and no longer runs on modern macOS; if you are a Mac user you might check out HexFiend, which is also available on the App Store). If you have a favorite Windows or Linux hex editor, please feel free to mention it in the comments for the other readers to check out.
(Update: So far suggested for Windows are WinHex, Hiew, XVI32, Hex Workshop, and the combined hex and text editor UltraEdit. For Unix-based systems hexcurse has been mentioned. Thanks!)
So what do the files look like? Here’s the beginning of cg.pd, which we can safely assume contains the game image files:
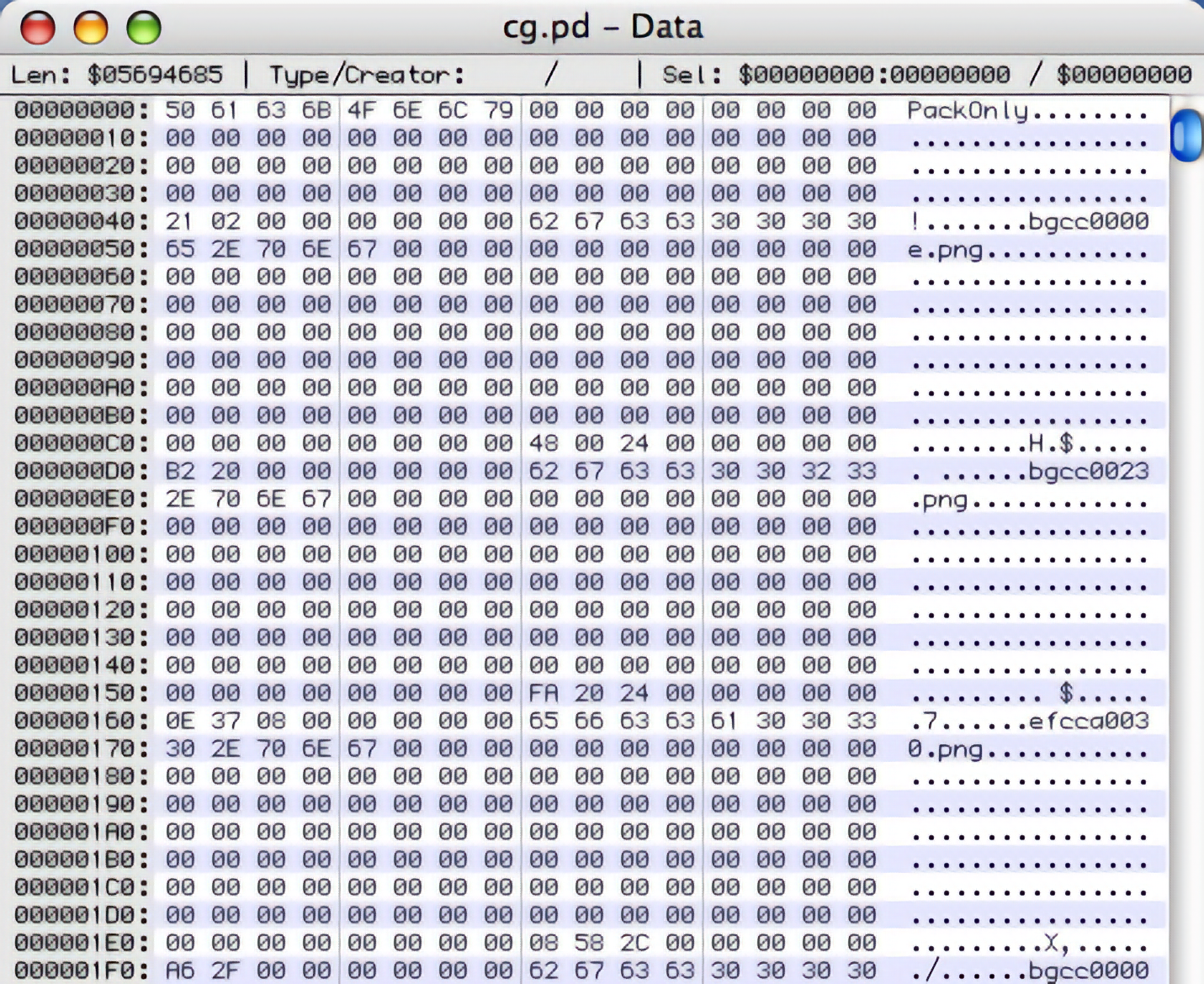
Yay, look at that: recognizable filenames! (Such as bgcc0000e.png.) If you see something like this, as opposed to just random bytes, you should rejoice. Even if you don’t know exactly what it all means yet, there is a clear path towards further interpretation.
To help us interpret what we’re looking at, it’s time for a brief digression on the contents of The Typical Game Archive.
- The Header
- Signature
Usually an archive will start with some sort of identifying string giving a signature for the archive format and version. You can use this as a way to make sure your utility is being run on the right type of file. - Index position
Most of the time, the archive index will start immediately, but sometimes the index is actually stored at the end of the file instead, since the archive packer doesn’t know how big it will be until afterwards (if the index is itself compressed, for instance). In that case, there will be a pointer to where the index is.
- Signature
- The Index
The key structure you will want to understand is the index of the archive contents, since it tells you how to get at the files contained inside.-
Index size
Usually the index will start with a size value, often simply the number of files contained in the index. This isn’t always the case, though, as sometimes instead the index will just continue until it hits a special ending entry (with, say, a negative file size or a null filename, etc.). -
List of file entries
Next there will be an list of the individual files contained in the archive. This can be either a constant- or variable-length data structure depending on how the filenames are handled. Sometimes there will be a hierarchical structure of filepaths to represent a whole directory tree inside, too. Each entry contains a number of standard bits of information:- Filename/filepath: can be a zero-terminated string, or sometimes the length will be explicitly given. Believe it or not, filenames are optional, as I’ve run across at least one case of a filename hash being stored instead.
- Position: an offet to the start of the file in the archive. Offsets can be from the start of the archive, the start of the index, or sometimes the start of the “file area” in the archive (i.e. an offset from the start of the contents of the first file, or equivalently from the end of the index).
- Size: how large the file is. This is sometimes left out, since it can often be inferred from the offset to the next file. Other times, there are two different sizes: an original size for the file, and the compressed size as it is stored in the archive.
- Flags: is the file compressed or not, and if so, with what algorithm? Is it encrypted, and if so, is there a key or initialization value to use?
- Checksum: to ensure data integrity, sometimes a checksum for the file will be given. This can be highly annoying for hackers, since it means that to modify the archive we will need to reverse-engineer the checksum algorithm to be able to compute appropriate values for our new data (or else disable the check in the executable).
Note that sometimes this information will be distributed, such as, say, the file position being given with the filename in an index structure, but the file size and compression flags given at that offset, right before the file data itself.
-
- The Files The files themselves are then just concatenated together in the archive, possibly compressed and possibly encrypted. The game engine knows where to find them from their index entries, so it can jump immediately to the ones it wants.
Okay, so let’s have a look at cg.pd from this perspective. The PackOnly sequence at the very beginning looks like an archive signature to me. Then it’s just a bunch of zero bytes until we hit offset 0×40, where we have the sequence 21 02 00 00 00 00 00 00 right before a recognizable ASCII-string filename.
Could this be the size of the index? Well, first of all, how do we interpret those bytes? We have a few choices:
- Random flag bytes. There are three bits set:
0×20and0×01in the first byte, and0×02in the second. Not unreasonable, but also not very useful. - Little-endian integer. Here
0×21is the least-significant byte,0×02is the next, etc. So the actual integer value is0×0000000000000221, or decimal 545. This could be a reasonable index size. - Big-endian integer(s). Now
0×21is the most-significant byte, and0×02the next, for an integer value of0×21020000, or decimal 553,779,200 (and we’re even ignoring the other four 00’s). This is kind of unreasonable since the whole file isn’t 500MB. Maybe it’s just a 16-bit integer:0×2102= 8450, which might work for, say, the byte-size of an index array.
Let’s check this. Scanning through the start of the file, it seems like the filenames start at offsets 0×48, 0xD8, 0×168, 0×1F8, 0×288, etc. That means that each one takes 144 bytes. The final filename (TCYM0005c.png) starts at offset 0×13248, which means that there are probably (0×13248-0×00048)/144 + 1 = 545 file entries.
Yay, 545! So the interpretation of 21 02 00 00 00 00 00 00 as a little-endian integer telling us how many file entries there are is probably correct. And even more importantly, now we can narrow our attention to those 144-byte areas, knowing that each one is likely a single file entry. Plus, we know that our archive likes little-endian integers, and perhaps prefers 8-byte ones as well.
Okay, let’s check out those file entries. But (and here’s a little trick of the trade) don’t look at the first one. Too many things are likely to be zero in the very first entry, so we’re not sure what to look at. Instead let’s check out the second entry, which we see runs from offset 0xD8 to 0×167:

We’ve got a filename, a lot of zeroes, and what look like two more 8-byte little-endian integers. Remember our template for The Typical Game Archive… we’re looking for size and position information, and maybe some of those zeroes are flag bytes, too, but there’s no way to know yet.
For now let’s assume that all the zeroes are part of the filename data structure: that gives exactly 128 bytes set aside for it, which sounds like a reasonable thing for a (lazy?) programmer to do. Then the leftover information are the integers 0×002420FA and 0×0008370E. Not quite sure what to make of these yet… but let’s get some more examples. What do the numbers look like for the first few files?
File 1 0×00240048 0×000020B2
File 2 0×002420FA 0×0008370E
File 3 0×002C5808 0×00002FA6
File 4 0×002C870E 0×00063B8A
File 5 0×0032C338 0×0006A7CB
Now it starts to make sense: the numbers in the first column are always getting larger, and moreover they’re always getting larger by exactly the amount in the second column! This is a perfect signature of an offset-and-size progression.
So, if our hypothesis is correct, the first file, bgcc0000e.png, should be 0×000020B2 = 8370 bytes long, and should probably start around offset 0×00240048 in the archive. We’re not entirely sure about that, since the offset could be counting or not counting the signature or the size of the index, and really that’s kind of suspicious since we think the index actually ends at offset 0×000132D7, remember. But let’s take a look anyway, since maybe the files are out of order:

Eureka! We’ve guessed exactly right, since right at offset 0×00240048 is the start of a PNG file. No compression, no encryption. In fact, if we copy-and-paste the next 8370 bytes into a new file and open it in a graphic editor, we are rewarded with… a 640×480 blank white screen.
Ummm. Well, games need white screens too, and at least the dimensions are sane. Let’s try the next image, just to be on the safe side, though. Grabbing 0×0008370E bytes starting at offset 0×002420FA gives us:

Yay! Victory is ours!
So, let’s summarize. We think the .PD format, at this point, consists of:
- Signature string
PackOnly - 56 bytes of zeroes
- 8-byte little-endian file count
- 144-byte file entry records consisting of:
- 128-byte filename, zero-terminated
- 8-byte little-endian file offset (from beginning of archive)
- 8-byte little-endian file size
- The files, uncompressed and unencrypted, at their offsets.
What should we make of the empty space between the end of the index and the start of the file data? Well, that offset 0×00240048 is suspicious… the first file entry was at 0×48, which means there are a total of 0×240000 bytes that could be used for file entries. At 144 bytes each, that means enough room for exactly 16384 files. This is, of course, 2¹⁴, which strikes me as exactly the sort of thing that a (lazy?) programmer would do: just set aside enough room for some large number of files.
Is this required? Maybe we can save a couple of megs when we rebuild the archives by getting rid of this blank space. Or maybe the game will crash if we move things by more than a byte… we’ll just have to see.
So, next time we’ll take our knowledge, and turn it into code. And naturally, we’ll run into some snags, heh heh.
Edward Keyes
Technical Lead
insani.org
Comments
roxfan @ May 29th, 2006 | 9:04 pm
Nice write-up. For Windows hex editors I prefer WinHex or Hiew. But there are plenty others, like 010 Editor, QView, tiny hexer etc etc.
Shii @ May 30th, 2006 | 12:10 am
Personally, I use xvi32.
http://www.chmaas.handshake.de/delphi/freeware/xvi32/xvi32.htm
Haeleth @ May 30th, 2006 | 3:16 am
UltraEdit-32 all the way. It’s incredibly convenient to have hex editing capability right there in my text editor.
Minase @ May 30th, 2006 | 7:48 am
I was going to comment on your first entry, saying “how can you teach something like this, other than showing example after example?”. Well, looks like that’s what you’re going to do :)
I like figuring out file formats or network protocols a lot… though i’m not terribly experienced as the need rarely comes along. So far i always use the same deduction and such as above. Looking for patterns, trying out theories, etc. The ‘manual’ way. What i’m interested in hearing about, though, is things like techniques for automated analysis that can help on really hard formats and give you hints as to what the data is… i’ve never looked into this, but i’ve heard other hackers say things here and there.
Also, techniques as to figuring out how to get data back when it’s been obfuscated. For me right now it’s just guess work, “oh what is this random looking sequence of 16 bytes in the header of file A? maybe if i xor it with this file that is nothing but garbage something will come out… hmm, no, okay, lets see if it’s an AES key then?” etc etc. I’d be interested in hearing if there is any way to make that process more efficient… Usually when people hide their data it’s laughably insecure, but still it’s very time consuming to figure out what they did.
I guess if i was really that bothered i’d have looked up resources on reverse engineering or whatever… so i’m not asking you to cover these type of things in your tutorial of course, but you do have my attention now :)
Regarding hex editors… I use ‘hexcurse’ in unix. Not that amazing, but serves it’s purpose. In windows, count another one in for XVI32 :) I love UltraEdit32 for code editing, but i don’t use it for hex editing. Maybe it’s got better? I still have an old version from Win95 days, doesn’t let you put spaces in filenames, crashes if you catch the scroll wheel by accident… :)
Haeleth @ May 30th, 2006 | 10:11 am
Um, yes, UltraEdit has definitely got better since 1994. O_O; Its hex editing isn’t terribly sophisticated, but it does everything I need as a hacker.
I’ve never heard of automated file format analysis before. The one form of automated analysis that I know and use is executable analysis — scanning the actual program to locate calls to interesting APIs, as a quick way of finding the section of code that loads a particular resource so you can reconstruct the format from the code that reads it. It’s possible Ed will get on to this (IIRC he’s the guy who introduced me to OllyDbg, which specialises in it), depending on whether CROSS†CHANNEL encrypts or compresses its scripts at all.
Edward Keyes @ May 30th, 2006 | 10:12 am
Heck, if there are good automated processes out there for making deductions, I wish I knew about them myself! Beyond a certain level of difficulty, though, I transition from file analysis and trial-and-error experimentation to taking a debugger to the original executable and seeing what it’s doing, and that will eventually get covered too.
Note, of course, that I’m by no means the ultimate expert here. There are certainly folks within the game-translation community that can run rings around my reverse-engineering ability, to say nothing of people in the wider game-cracking circles. I’m mainly just trying to get the learning process started with this tutorial series — hopefully down the line I can arm-twist some other folks into submitting writeups of their own about especially interesting hacking they’ve done. :)
PS- CROSS†CHANNEL is just a starting choice, since it has an easy-to-understand basic data format. I’ll be switching to other games later on when I need a better example of, say, a custom image format, or compression and encryption, etc. And of course if people have games that they’d specifically like to see covered, please feel free to suggest them.
Shish @ June 4th, 2006 | 2:43 pm
So we know better what to look for, what formats are commonly used? I would guess PNG / JPEG / BMP(?) for images, Ogg Vorbis / MP3 for sound, zlib for compression, and xor / RC4 for encryption — could someone with some experience comfirm / deny?
Edward Keyes @ June 4th, 2006 | 2:57 pm
Yep. For images, PNG/JPEG/BMP are all common, as are (unfortunately) completely custom image formats, which will be a topic for a later entry. For sounds, Ogg Vorbis/MP3/WAV are common, and thankfully that’s about all — plus they’re almost always stored uncompressed and unencrypted for streaming playback from disk, so they’re great hooks to understand archives with. For compression, zlib is a good one to look for, but different variants of LZSS and Huffman encoding are also prevalent (another later topic), as is run-length compression in some custom image formats. And for encryption, you have everything from a simple one-byte XOR to custom stream ciphers up to industrial-strength encryption like Blowfish (another later entry!). Haven’t run across RC4 yet but it wouldn’t surprise me either.
Haeleth @ June 5th, 2006 | 3:25 pm
Note that one or two custom sound formats are quite common — one notorious offender being the VisualArt’s .nwa format, used for voices and music in most of their commercial releases (even where the demos use Ogg Vorbis — explain that one if you can!)
Shish @ June 6th, 2006 | 8:50 pm
Writing a multi-format extractor to familiarise myself with these things (and C++); I note that there are a lot of easy to read formats used by one game each, and only a couple of hard to read formats that seem to be used a lot — I take it this represents a market with a lot of simple custom made engines, and one or two professional quality general use ones? (Sample data comes from going to holyseal.net, and clicking randomly until I find links with “trial” and “.exe” in them and a number less than 100MB to the side)
Joseph LaRoza @ May 16th, 2007 | 8:44 am
HxD is a good, free hex editor.